
React was created to provide declarative, modular, and cross-platform interactive UIs. It is now one of the most used JavaScript frameworks for creating performant front-end apps, if not the most popular. React was originally designed to generate single-page applications (SPAs), but it is now now used to build full-fledged websites and mobile apps.
If you have a lot of expertise with traditional web development and switch to React, you’ll find that more and more of your HTML and CSS code is being converted to JavaScript. This is because React recommends expressing the “state” of the UI rather than immediately building or modifying it. React will then update the DOM in the most efficient way possible to match the state.
As a result, all UI and DOM modifications must be made through React’s engine. While this is beneficial to developers, it may result in higher loading times for users and more work for search engines to identify and index the information.
In this article, we’ll go through some of the issues that come up while designing SEO-friendly React apps and websites, as well as some of the tactics that have helped us overcome them.
How Google Indexes and Crawls Webpages
Over 90% of all online searches are directed to Google. Let’s look at the crawling and indexing procedure in more detail.
This screenshot from Google’s documentation may be of assistance. Please keep in mind that this is an abridged block diagram. The real Googlebot is a lot more advanced.
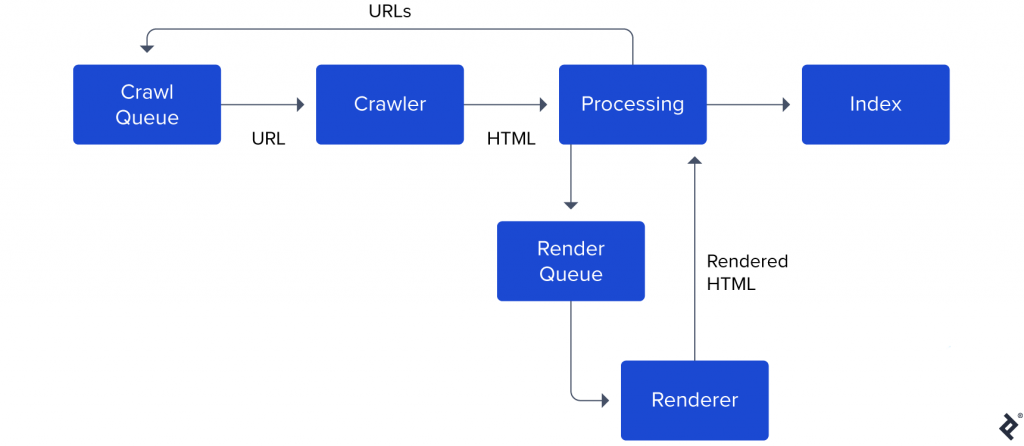
Points to note:
- Googlebot maintains a crawl queue containing all the URLs it needs to crawl and index in the future.
- When the crawler is idle, it picks up the next URL in the queue, makes a request, and fetches the HTML.
- After parsing the HTML, Googlebot determines if it needs to fetch and execute JavaScript to render the content. If yes, the URL is added to a render queue.
- At a later point, the renderer fetches and executes JavaScript to render the page. It sends the rendered HTML back to the processing unit.
- The processing unit extracts all the URLs
<a> tagsmentioned on the webpage and adds them back to the crawl queue. - The content is added to Google’s index.
There is a distinct difference between the Processing stage, which parses HTML, and the Renderer stage, which runs JavaScript.
Because Googlebots must look at over 130 trillion URLs, this distinction exists because executing JavaScript is costly. When Googlebot scans a webpage, it first parses the HTML and then queues the JavaScript for subsequent execution. According to Google’s documentation, a page stays in the render queue for a few seconds, although it might be longer.
It’s also worth discussing the crawl budget notion. The bandwidth, duration, and availability of Googlebot instances limit Google’s crawling. It allots a certain amount of money or resources to each website’s indexing. If you’re creating a huge content-heavy website with thousands of pages (e.g., an e-commerce site), and these pages employ a lot of JavaScript to produce the information, Google might be able to read less of it.
Note: You can read Google’s guidelines for managing your crawl budget here.
Why Optimizing React for SEO Is Challenging
Our overview of Googlebot, crawling, and indexing is only the tip of the iceberg. However, software engineers should be aware of potential difficulties that search engines may encounter when crawling and indexing React pages. Now we can examine what makes React SEO difficult, as well as what developers may do to address and overcome some of these issues.
Empty First-pass Content
We know that React applications mainly rely on JavaScript, and that they frequently encounter issues with search engines. Because React uses an app shell model by default, this is the case. The page’s initial HTML contains no significant content, so a human or a bot must run JavaScript to see the page’s true content.
Because of this method, Googlebot finds an empty page on the first run. Google only sees the content when the page is rendered. When dealing with thousands of pages, this will cause the indexing of content to be delayed.
Loading Time and User Experience
It takes time to fetch, parse, and execute JavaScript. Furthermore, JavaScript may need to make network calls to obtain the content, which means the user may have to wait a bit to see the requested information.
Google has outlined a set of site vitals that are included in its ranking factors and are connected to user experience. A longer loading time may have an impact on the user experience score, causing Google to reduce a site’s ranking.
In the following section, we go through the performance of the website in great depth.
Page Metadata
<Meta> tags are useful because they allow Google and other social media sites to display relevant page titles, thumbnails, and descriptions. However, these websites rely on the fetched webpage’s <head> tag to obtain this information. For the target page, these websites do not use JavaScript.
On the client, React renders all content, including meta tags. Because the app shell is the same for the entire website/application, customizing metadata for different pages may be difficult.
Sitemap
A sitemap is a file that contains information about your site’s pages, videos, and other files, as well as their relationships. This file is accessed by search engines like Google to help them crawl your site more intelligently.
There is no built-in solution to generate sitemaps with React. You can discover tools that can produce a sitemap if you’re using something like React Router to manage routing, however it may take some effort.
Other SEO Considerations
These factors all have to do with establishing strong SEO strategies in general.
- To provide humans and search engines a solid notion of what to expect on the page, use an ideal URL format.
- The robots.txt file can be optimized to help search spiders understand how to crawl your website’s pages.
- To reduce load times, use a CDN to provide all static files such as CSS, JS, and fonts, and employ responsive images.
Using server-side rendering (SSR) or pre-rendering, we can solve many of the issues listed above. We’ll go over each of these options in more detail below.
Enter Isomorphic React
Isomorphic means “corresponding or comparable in form,” according to the dictionary.
This means that the server has a form that is similar to the client in React. In other words, the same React components can be used on both the server and the client.
This isomorphic technique allows the server to display the React app and transmit the rendered version to our users and search engines, allowing them to see the content immediately as JavaScript loads and executes in the background.
This strategy has become popular thanks to frameworks like Next.js and Gatsby. It’s worth noting that isomorphic components can appear rather different from standard React components. They can, for example, incorporate code that executes on the server rather than the client. They can even contain API keys (although server code is stripped out before being sent to the client).
It’s worth noting that while these frameworks abstract away a lot of complexity, they also offer an opinionated approach to code authoring. In this essay, we’ll go deeper into the performance trade-offs.
We’ll also run a matrix analysis to figure out how render pathways affect website speed. But first, let’s go through the fundamentals of assessing website performance.
Metrics for Website Performance
Let’s look at some of the elements that search engines consider when ranking webpages.
Apart from swiftly and precisely answering a user’s question, Google feels that a good website should include the following characteristics:
- It should be quick to load.
- Users should be able to access content without having to wait for long periods of time.
- It should become interactive with the user’s activities as soon as possible.
- To avoid exhausting a user’s data or battery, it should not fetch unneeded data or execute expensive code.
These characteristics roughly correspond to the following metrics:
- Time to First Byte (TTFB) is the time between clicking a link and receiving the first byte of content.
- The time when the requested article gets displayed. LCP: Largest Contentful Paint This value should be kept under 2.5 seconds, according to Google.
- TTI stands for Time To Interactive and refers to the point at which a page becomes interactive (a user can scroll, click, etc.).
- The total number of bytes downloaded and code run before the website became completely visible and interactive is referred to as the bundle size.
We’ll go over these metrics again to see how different rendering paths affect each of them.
Let’s look at the many render pathways available to React developers next.
Render Paths
A React application can be rendered in the browser or on the server, with various outputs.
Routing and code splitting are two features that differ dramatically between client-side and server-side generated apps. We take a closer look at these below.
Client-side Rendering (CSR)
A React SPA’s default render path is client-side rendering. The server will deliver a shell application with no content. The HTML content is populated or rendered once the browser downloads, parses, and executes included JavaScript sources.
The client app manages the browser history to handle the routing function. This means that regardless of which route was requested, the same HTML file is served, and the client’s view state is updated when it is rendered.
Splitting the code is a simple process. You can use dynamic imports or React.lazy to separate your code so that only the dependencies that are needed are loaded based on route or user actions.
If the page has to fetch data from the server to render content (for example, a blog title or a product description), it can only do so after the appropriate components have been mounted and rendered.
While the website downloads further data, the user will most likely see a “Loading data” sign or indicator.
Client-side Rendering With Bootstrapped Data (CSRB)
Consider the same case as CSR, except instead of downloading data after the DOM has been rendered, the server has supplied necessary data bootstrapped inside served HTML.
A node that looks somewhat like this could be included:
<script id="data" type="application/json">
{"title": "My blog title", "comments":["comment 1","comment 2"]}
</script>And parse it when the component mounts:
var data = JSON.parse(document.getElementById('data').innerHTML);We just saved ourselves a round trip to the server. We will see the tradeoffs in a bit.
Server-side Rendering to Static Content (SSRS)
Consider the following scenario: we need to build HTML on the fly.
For example, suppose we’re constructing an online calculator and a user types in /calculate/34+15 (leaving out URL escaping). We must perform the query, assess the result, and respond with HTML that has been prepared.
Because our generated HTML has a simple structure, we don’t require React to manage and alter the DOM after it’s provided.
As a result, we’re only serving HTML and CSS material. To accomplish this, utilise the renderToStaticMarkup function.
Because the server must recompute HTML for each result, the server will handle all routing. However, CDN caching can be employed to serve results faster. The browser can also cache CSS files to speed up subsequent page loads.
Server-side Rendering with Rehydration (SSRH)
Consider the identical scenario as before, but with the addition of a fully functional React application on the client.
The first render will be done on the server, and the HTML content will be returned together with the JavaScript files. The server-rendered markup will be rehydrated by React, and the application will now operate like a CSR application.
These activities can be performed using React’s built-in methods.
The server handles the first request, while the client handles subsequent renderings. As a result, such apps are referred to as universal React apps (rendered on both server and client). On the client and server, routing code might be separated (or duplicated).
Because ReactDOMServer does not allow React. lazy, you may need to utilise something like Loadable Components to separate the code.
It’s also worth noting that ReactDOMServer only renders a shallow version of the page. In other words, while your components’ render methods will be called, life-cycle methods such as componentDidMount will not. As a result, you’ll need to restructure your code to use a different mechanism to give data to your components.
This is where frameworks such as NextJS come into play. They hide the complexity of SSRH routing and code splitting, resulting in a more pleasant development experience.
As we’ll see in a moment, this strategy has mixed results in terms of page performance.
Pre-rendering to Static Content (PRS)
What if we could render a webpage before it was requested by a user? This could be done either at the time of construction or dynamically when the data changes.
The generated HTML content can then be cached on a CDN and served significantly faster when a user wants it.
This is known as pre-rendering, and it occurs before the content is rendered, or before to the user’s request. Because the content of blogs and e-commerce applications does not often rely on data supplied by the user, this strategy can be used.
Pre-rendering with Rehydration (PRH)
When a client renders our pre-rendered HTML, we may want it to be a fully working React app.
The application will function like a typical React app after the first request is served. In terms of routing and code-splitting functions, this mode is comparable to SSRH, as mentioned above.
Performance Matrix
It’s finally here: the moment you’ve been waiting for. It’s time for a fight. Let’s take a look at how each of these rendering routes affects web speed metrics to see who comes out on top.
We award a score to each rendering path in this matrix based on how well it performs in a performance criterion.
The scale runs from 1 to 5, with 1 being the lowest and 5 being the highest.
- 1 = Unsatisfactory
- 2 = Poor
- 3 = Moderate
- 4 = Good
- 5 = Excellent
| TTFB Time to first byte | LCP Largest contentful paint | TTI Time to interactive | Bundle Size | Total | |
|---|---|---|---|---|---|
| CSR | 5 HTML can be cached on a CDN | 1 Multiple trips to the server to fetch HTML and data | 2 Data fetching + JS execution delays | 2 All JS dependencies need to be loaded before render | 10 |
| CSRB | 4 HTML can cached given it does not depend on request data | 3 Data is loaded with application | 3 JS must be fetched, parsed, and executed before interactive | 2 All JS dependencies need to be loaded before render | 12 |
| SSRS | 3 HTML is generated on each request and not cached | 5 No JS payload or async operations | 5 Page is interactive immediately after first paint | 5 Contains only essential static content | 18 |
| SSRH | 3 HTML is generated on each request and not cached | 4 First render will be faster because the server rendered the first pass | 2 Slower because JS needs to hydrate DOM after first HTML parse + paint | 1 Rendered HTML + JS dependencies need to be downloaded | 10 |
| PRS | 5 HTML is cached on a CDN | 5 No JS payload or async operations | 5 Page is interactive immediately after first paint | 5 Contains only essential static content | 20 |
| PRH | 5 HTML is cached on a CDN | 4 First render will be faster because the server rendered the first pass | 2 Slower because JS needs to hydrate DOM after first HTML parse + paint | 1 Rendered HTML + JS dependencies need to be downloaded | 12 |
Key Takeaways
Pre-rendering to static content (PRS) produces the best results, however server-side rendering with hydration (SSRH) or client-side rendering (CSR) may produce disappointing results.
It’s also feasible to use different strategies for different portions of the website. These performance measures, for example, may be crucial for public-facing webpages in order for them to be indexed more efficiently, but they may be less important once a user has checked in and views private account data.
Each render path provides a tradeoff between where and how you want your data to be processed. What matters is that an engineering team can easily perceive and discuss these tradeoffs in order to select an architecture that maximizes their consumers’ enjoyment.
Additional Reading and Thoughts
While I attempted to cover the most common strategies at the time, this is not a thorough examination. I strongly advise you to read this article, in which Google developers explore various sophisticated rendering techniques such as streaming server rendering, trisomorphic rendering, and dynamic rendering (serving different responses to crawlers and users).
Other things to think about while creating content-heavy websites are the requirement for a robust content management system (CMS) for your authors, as well as the capacity to quickly generate/modify social media previews and optimize images for different screen sizes.
